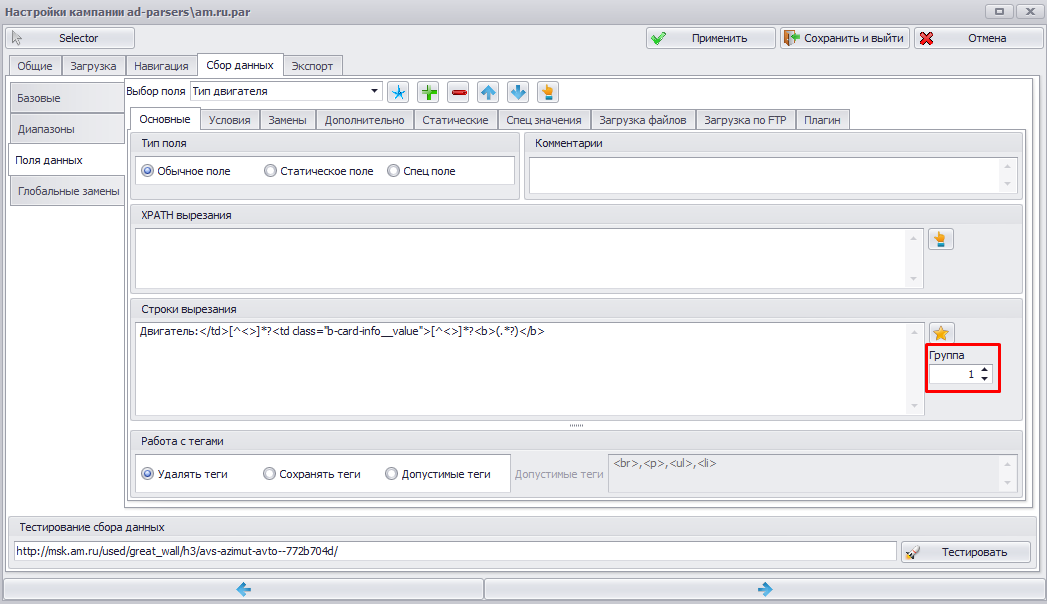
Datacol в настройках сбора данных поддерживает использование так называемых Групп регулярного выражения. Ниже мы подробно объясним, что они собой представляют.
Иногда вам может понадобиться получить больше информации о соответствии, чем простая индикация присутствия шаблона во входящем потоке. Например, при поиске числа с использованием следующего шаблона:
\d+
вы , возможно, захотите извлечь фактический текст с найденным числом. Это одна из ситуаций, в которых полезны группы регулярных выражений. Группа - это пронумерованная часть регулярного выражения. Например, в следующем выражении
(\d+)zzz
присутствуют две группы. Группа 0 всегда относится ко всему выражению, а группа 1 - к подвыражению, начинающемуся с открывающей круглой скобки "(" и заканчивающемуся закрывающей круглой скобкой ")". Текст соответствующих групп сохраняется обнаружителем соответствий регулярного выражения и может быть извлечен в дальнейшем в регулярном выражении.
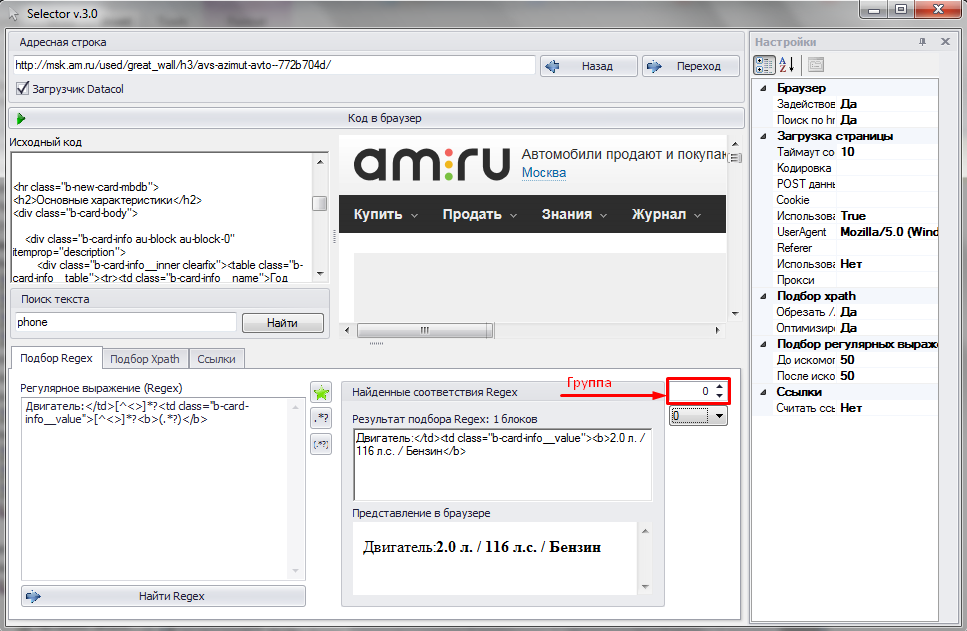
Использование групп можно продемонстрировать на примере в Selector. На первом скриншоте мы получим нулевую группу совпадения регулярного выражения.
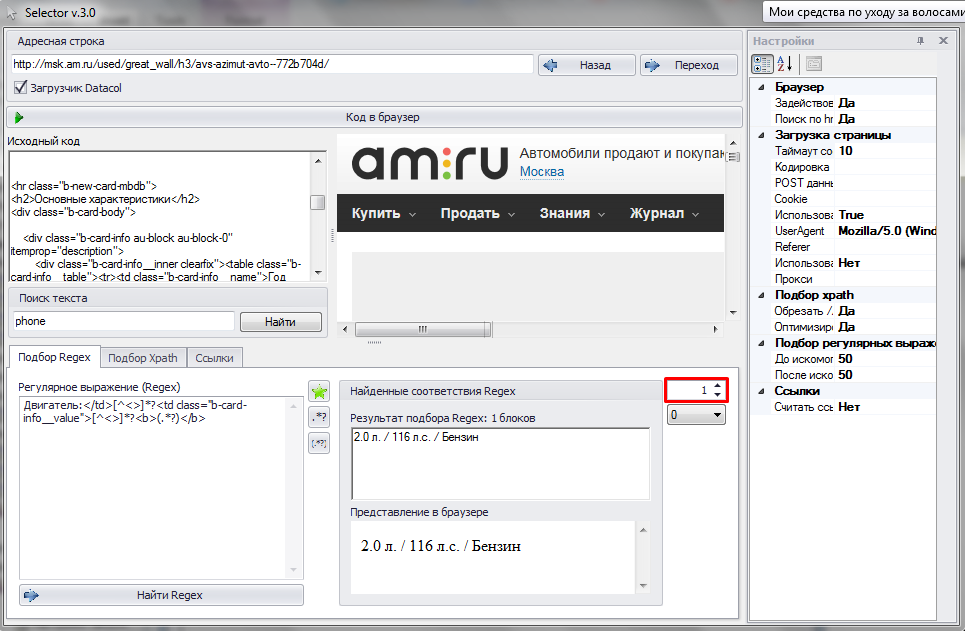
На втором скриншоте мы для того же самого регулярного выражения получим первую группу:
Created with the Personal Edition of HelpNDoc: Free iPhone documentation generator