

Наша команда более 10 лет создает парсера документов и вебстраниц. Хочется поделиться опытом о типичных «граблях», на которые наступают заказчики и разработчики парсеров инвойсов, спецификаций и прочих документов. Если же вам лень разбираться в этих нюансах — напишите в нашу поддержку и мы договоримся о консультации. Мы с радостью подскажем вам, как можно быстро спарсить нужные вам документы, даже если у них сложная и непредсказуемая структура.
1. Плохое качество
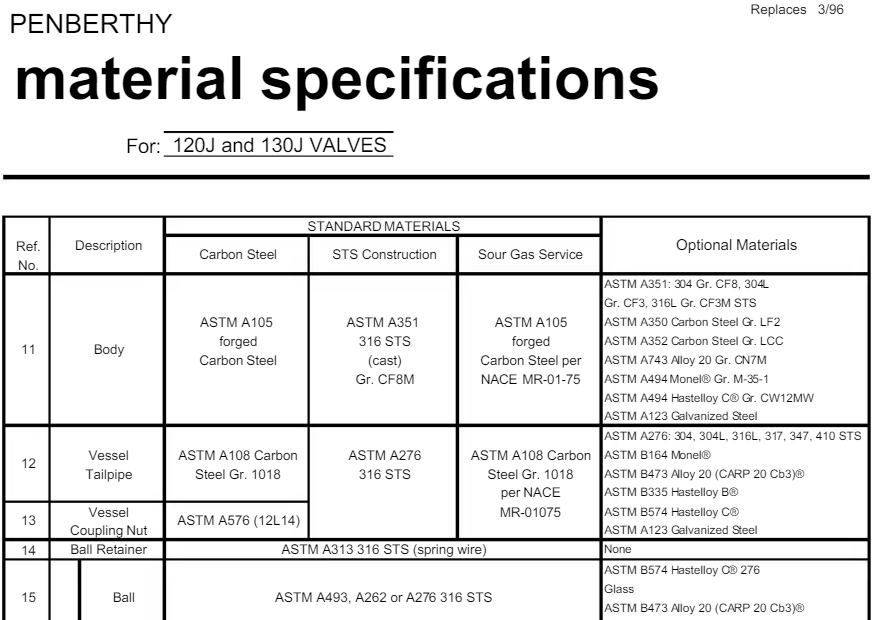
Одной из самых больших проблем парсинга документов является плохое качество исходных материалов. Часто документы предоставляются в виде сканов или фотографий, что приводит к следующим трудностям:
- Размытые изображения: Сканы или фотографии могут быть нечеткими, что затрудняет распознавание текста.
- Низкое разрешение: Низкое качество изображения снижает точность оптического распознавания символов (OCR).
- Шумы и артефакты: Пятна, линии, загибы бумаги и другие артефакты могут мешать правильному распознаванию текста.
- Рукописный текст: Рукописные заметки или подписи часто оказываются трудными для автоматического распознавания.
Для преодоления этих трудностей используются алгоритмы предобработки изображений, такие как фильтрация шумов, улучшение контрастности и сглаживание. Также применяются специализированные OCR-модели, обученные на рукописных текстах или низкокачественных изображениях.
2. Разный layout
Вторая основная сложность заключается в разнообразии макетов документов. Инвойсы, накладные и спецификации могут сильно различаться по структуре и формату:
- Разнообразие шаблонов: Каждый поставщик или клиент может использовать свой собственный шаблон документов, что делает невозможным создание универсального алгоритма для их парсинга.
- Изменения в форматах: Компании могут периодически менять свои шаблоны, что требует постоянного обновления парсинговых алгоритмов.
- Различные языки и форматы дат: Документы могут содержать информацию на разных языках, а также различные форматы дат и чисел, что усложняет их интерпретацию.
Для решения этих проблем используются методы машинного обучения и NLP, которые обучаются на большом количестве примеров различных шаблонов и могут адаптироваться к новым форматам. Также применяются правила и шаблоны, которые помогают выделять ключевые поля и информацию.
3. Неоднородность данных
Третья важная сложность – это неоднородность данных, которая проявляется в следующем:
- Инконсистентность данных: Один и тот же тип информации может быть представлен по-разному в разных документах (например, адреса, названия товаров).
- Ошибки и опечатки: Документы могут содержать ошибки и опечатки, которые затрудняют автоматическое распознавание и обработку данных.
- Отсутствие данных: Некоторые поля могут быть пустыми или содержать неполную информацию, что требует дополнительной обработки и проверки.
Для борьбы с этими проблемами используются методы нормализации и стандартизации данных, а также алгоритмы исправления ошибок. Кроме того, внедряются системы проверки и валидации данных, которые помогают выявлять и исправлять некорректные или отсутствующие данные.
Заключение
Парсинг документов, таких как инвойсы, накладные и спецификации, сопряжен с рядом сложностей, включая плохое качество исходных материалов, разнообразие макетов и неоднородность данных. Для их преодоления необходимо использовать комплексный подход, включающий современные методы машинного обучения, NLP, предобработку изображений и алгоритмы нормализации данных. Это позволяет создавать эффективные и точные системы для автоматического распознавания и обработки документов.
UPDATE! Недавно поделились кейсом парсинга сложных PDF для крупного оптовика оргтехники.








