

Парсер pdf — распознавание неструктурированных данных
Проблематика
Крупный оптовик офисной техники получает множество ценников и каталогов товаров от различных производителей в формате PDF. Форматы документов сильно различаются, что усложняет автоматическую обработку и интеграцию данных в систему управления запасами. Ручная обработка таких файлов не только требует значительных временных затрат от сотрудников, но и подвержена ошибкам из-за человеческого фактора.
Цель проекта
Автоматизировать процесс распознавания и конвертации данных из PDF в структурированный формат, сократить время обработки и минимизировать ошибки.
Решение
Разработка системы на базе технологии оптического распознавания символов (OCR) в сочетании с языковыми моделями (LLM) для обработки и структуризации данных:
- Выбор инструментов OCR: Использование передовых OCR-систем, способных эффективно работать с разнообразными форматами текста, включая те, что имеют сложные макеты и разнообразные шрифты.
- Интеграция LLM: Применение языковых моделей для понимания контекста распознанного текста, что позволяет не только извлекать данные, но и классифицировать их по категориям (например, наименование товара, цена, количество на складе).
- Обучение модели: Настройка и обучение модели на специфичных данных, полученных от производителей. Это включает в себя обучение модели распознавать и корректно обрабатывать различные стили оформления документов.
- Итерации и улучшение: Постепенное улучшение системы на основе обратной связи от пользователей и анализа ошибок.
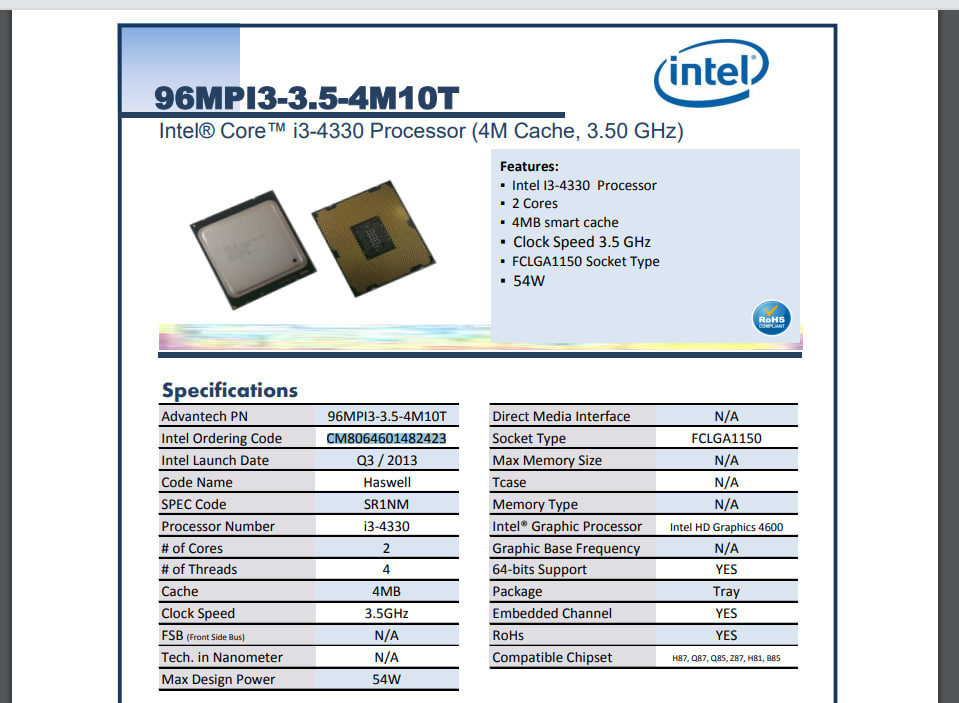
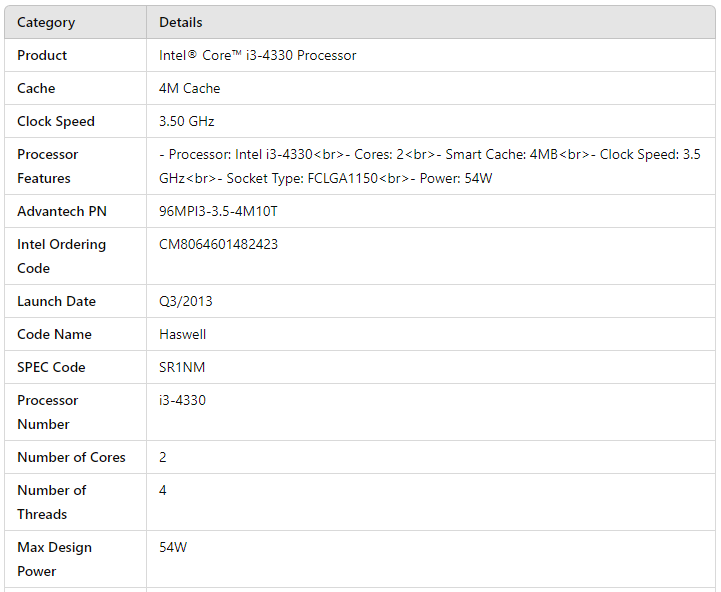
Пример работы системы
- Вход: PDF-файл с каталогом товаров, где товары представлены в табличной форме с изображениями, описаниями и ценами.
- Процесс: Файл обрабатывается OCR для преобразования содержимого в текст, после чего LLM анализирует структуру данных, распознает и классифицирует информацию по соответствующим полям.
- Выход: Структурированный файл (например, CSV или JSON), где каждая строка содержит информацию о товаре с разбивкой по столбцам: наименование, описание, цена, наличие.
Результаты и пути развития
Система позволила автоматически обрабатывать около 85% входящих PDF без дополнительного вмешательства. Для оставшихся 15%, требующих дополнительной настройки из-за сложного дизайна или нестандартной структуры, рассматривается возможность доработки алгоритмов распознавания или введения частичного ручного управления для сложных случаев.
Нужна консультация?
Если вам нужна система для конвертации pdf в excel или другой структурированный формат, напишите в нашу поддержку и мы договоримся о консультации. Мы с радостью подскажем вам, как можно применить AI для решения вашей задачи.








