Парсинг нескольких больших изображений товара на примере rozetka.com.ua
Большие изображения можно спарсить без написания дополнительных плагинов Datacol только в том случае, если ссылки на них (относительные или абсолютные) доступны в исходном коде загруженной страницы.
Алгоритм сохранения нескольких больших изображений следующий:
1. Пробуем подобрать xpath. Для этого кликаем мышкой на картинку, создается xpath:
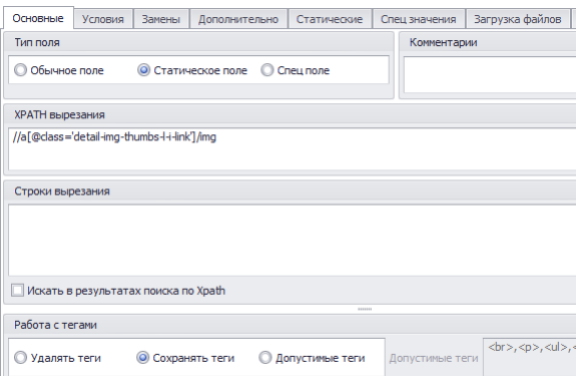
//div[@class=’detail-img-thumbs-l-i active’]/a[@class=’detail-img-thumbs-l-i-link’]/img.
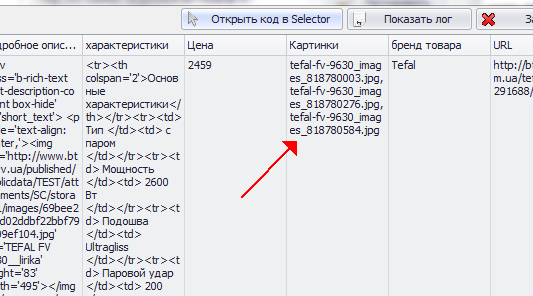
При этом он подходит только 1-й картинке:
2. Нажимаем кнопку “Обрезание слева”. Видим, что теперь все картинки выделяются красной рамкой:

3. Жмём “Сохранить и выйти”.
4. Для того, чтобы html-код полученного изображения отображался в ячейке, включаем опцию “Сохранять тэги”.
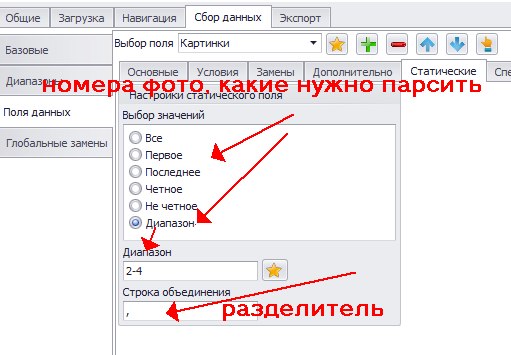
5. Чтобы парсилась не одна, а сразу несколько фотографий, включаем опцию “Статическое поле”.
При этом картинки будут сохраняться в 1 ячейку через “,”.
6. Для изменения разделителя (и других опций) переходим на вкладку “Статическое поле”.
7. Чтобы картинки сохранялись на диск, переходим на вкладку “Загрузка файлов”, включаем опцию “Загружать файлы” и тестируем сохранение фото:
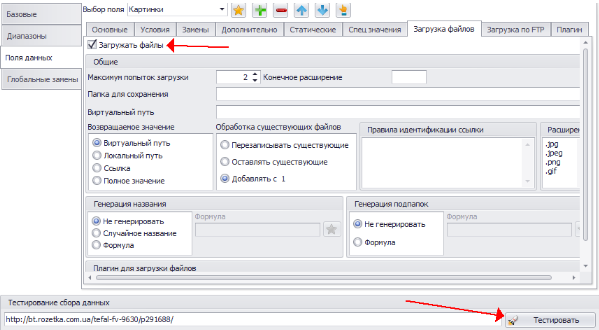
После тестирования переходим в папку “Мои изображения”, видим что фото скачались, но маленького размера, а нам нужны большие фото.
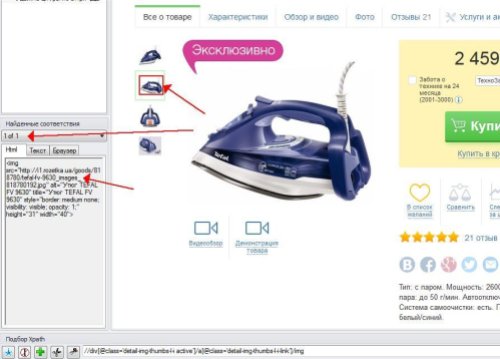
8. Открываем код в Selector:
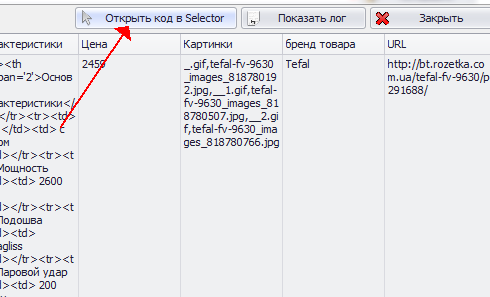
9. Также открываем страницу в вашем браузере по умолчанию. Для этого делаем клик по полю URL в окне результатов тестирования, или вставляем ссылку на карточку товара вручную в ваш браузер.
10. На сайте rozetka.com.ua большое фото открывается при нажатии на него. Открываем большое фото и копируем ссылку на изображение (для этого кликните по изображению правой кнопкой мыши).

11. Находим место в коде, где все нужные изображения находятся в одном месте. В данном случае, ссылки на изображения в оригинальном размере можно найти в коде страницы в javascript:
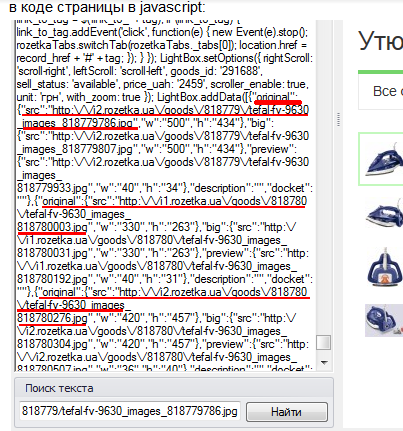
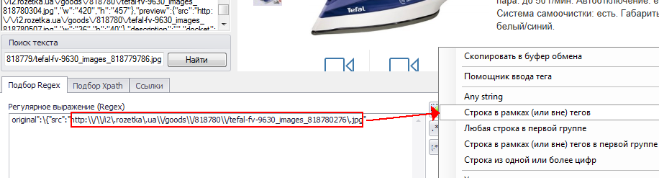
12. Подбираем Regex для 1-го из требуемых изображений. Для этого выделяем курсором нужную часть кода, кликаем на неё правой кнопкой мыши и нажимаем “Создать Regex как шаблон”. В результате получаем Regex, который подходит для данного конкретного изображения:
original»:\{«src»:»http:\\/\\/i2\.rozetka\.ua\\/goods\\/818780\\/tefal-fv-9630_images_818780276\.jpg»
13. Чтобы regex подходил для всех изображений, заменяем ссылку в полученном выражении на один из стандартных шаблонов:
14. Был подобран regex: original»:\{«src»:»[^<>]*?». Чтобы вырезать не весь текст, а только его часть, можем заключить нужную часть кода (ссылку на изображение) в скобки: original»:\{«src»:»([^<>]*?)»
15. Копируем полученный regex в настройку. Удаляем полученный ранее xpath и устанавливаем 1-ю группу, чтобы получить ссылку без лишнего кода (фрагмент из regex, заключённый в скобки).
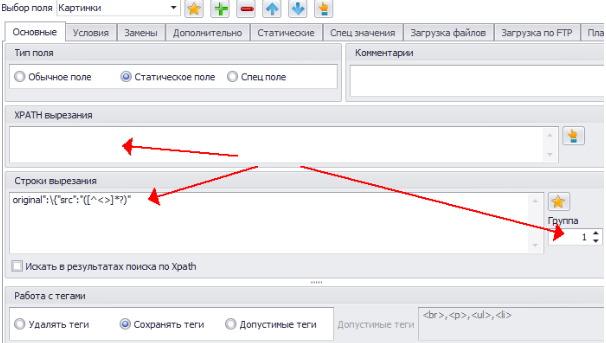
16. При подборе regex-выражения для изображений в Selector, можно заметить, что ссылки в javascript коде выглядят так:
http:\/\/i2.rozetka.ua\/goods\/818779\/tefal-fv-9630_images_818779786.jpg
вместо необходимого:
http://i2.rozetka.ua/goods/818779/tefal-fv-9630_images_818779786.jpg
Для устранения данной неприятности переходим на вкладку “Замены” и создаем новую замену: “\/” на “/”. Теперь получаем ссылку нужного нам вида:

17. Тестируем полученную настройку. Переходим в папку “Мои изображения” и видим все необходимые фото большого размера, а в результатах тестирования отображаются названия этих файлов: